
Dear Reader,
together with a group of people (see at the end) we have organized workshops about Quantum Resource Estimation at IEEE Quantum Week 2023 in Seattle. We had a set of amazing speakers who talked about the topic from various perspectives and in this post, I would like to summarize their talks.
We have grouped the workshop into three sessions:
- Grand Challenges
- Machinery
- Tools demonstrations
While writing this post I realized the style of each section is a bit inconsistent. That’s because the talks had different formats, so in some cases it felt more appropriate to follow the narrative of the talk closely, in other just provide a summary of their points. Hope it works well :)
As it took me long to write this blog post, I didn’t want to delay publishing it, so I have not asked any of the speakers to authorize the text! I hope I have not misrepresented anything, but if something seems suspicious, this might be the reason why.
Ok, let’s dive in!
Grand Challenges
Travis Humble
Travis Humble – director of Quantum Science Center at Oak Ridge National Laboratory.
Travis started from talking about four characteristics of quantum computers:
- Area: footprint of the algorithm, in the circuit model that would be depth * width.
- Error: drives how well the machine can operate and how much overhead is needed for error mitigation/correction.
- Latency: not a bottleneck right now, but might be important in the future. I think it could be related to the reaction depth problem that others mentioned in their talks.
- Accuracy: being able to quantify whether the answers are accurate is an important aspect of performing resource estimates.
From the perspective of applications it’s also important to estimate what is time-to-solution and power needed to run particular program.
He also mentioned some key challenges present in quantum computing now.
- Managing diversity – there are many platforms and all of them change rapidly. In the context of QRE, you need to take into account the constraints and capabilities of a particular system.
- Noise and errors – error mitigation and correction consume a lot of resources. It’s interesting to see how these methods develop (e.g.: Y. Kim et al ).
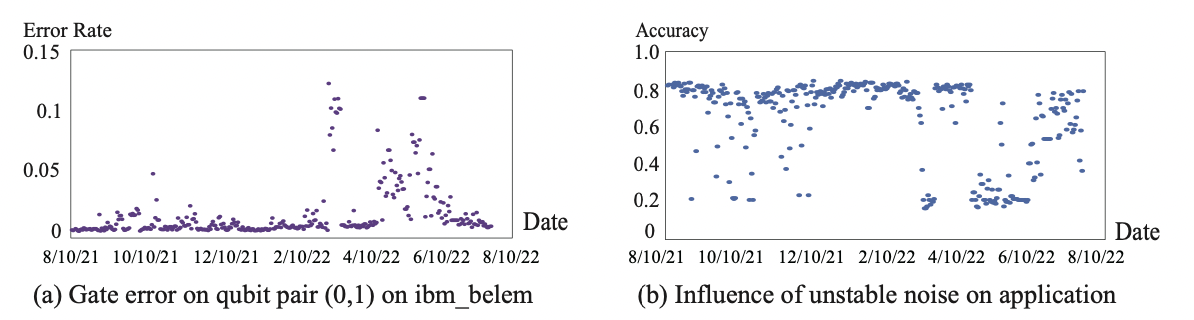
- Model validation – we need to make sure that the model we use (either for performing error mitigation/correction or QRE) is valid. This is not trivial, as the characteristics of the devices today can change drastically over time. (see below, it’s Fig. 1 from Zhu et al. ).
- Reproducibility – given the point above, being able to reproduce any results is also not trivial and something we don’t think about enough as a community.
Travis spent significant time talking about the last one. He defined reproducibility as the ability to reproduce the results from an experiment under identical conditions (within statistical confidence).
It is a grand challenge in part because it sets expectations for behavior we really can’t meet. We can’t create identical conditions to meet the point-model estimates and we need to figure out the way to connect those point-models.
I think it’s important to talk a bit about models at this point. One of the problems with QRE is that in order to get any hardware-aware numbers, you need to have some model of the hardware that you use to produce those estimates. Therefore, your estimates will be only as good as the model you use. In this context “point-model” means “model of your hardware at a given point in time”. So my interpretation of what Travis said, is that rather than relying on point models, we need to figure out a way to build more realistic models and characterize the hardware better.
He also said that understanding how variation in hardware, different noise models, etc. influence the metrics we actually care about (accuracy and time-to-solution) will be an important task.
The whole talk focused on near-term devices, but many wondered how this maps to the FTQC regime. Travis admitted, that this might be just a phase in the development of the hardware and perhaps this problem will not exist in the FTQC regime. However, it might also be true that even with error correction models for various parts of the systems are different and unstable over time, which might affect the performance and resources needed for the calculation.
Wim van Dam
Wim van Dam – Principal Researcher at Microsoft.
This talk was based on some of the research Wim and his team did in the past. Some of it has not been yet published, I’ll link to it when it’s out. Here’s a paper he was referring to, as well as Azure Quantum Resource Estimator.
Wim started his talk strong: What’s the purpose of talking about QRE? Given how big those numbers are, is it just to get depressed?
Well – no. We should take QRE seriously right now. Why? Because they will help us find good applications for QC.
What applications are we talking about? Something that’s actually important, classically amenable, and can be solved within weeks, not years. A good rule of thumb for the target execution time is a million seconds (which is roughly 12 days). A “practical quantum solution”.
Next, Wim talked a bit about the model of the stack they’ve been using for their QRE:
- Error rates per gate: \(10^{-11}\) to \(10^{-16}\). This implies that we need QEC.
- The error correction code used is planar, but it can be either surface code or Floquet code.
- Given the choice of code, you choose the type of instructions (either gate or Majorana-based) and then the type of hardware.
- Stack is divided into three levels: logical qubits, QEC and physical qubits
Using this model, they’ve chosen various sets of parameters: optimistic, pessimistic and based on Majorana (if you’re not sure what that means, but there’s explanation in the paper).
After getting QREs, the problem is that some of the estimates they got take more than 2 weeks. However, having these numbers (even if they’re a bit depressing) allows us to better articulate the needs of the application.
Then they asked, whether there’s a single number, that summarizes the core strength of the hardware and they came up with rQOPS (reliable Quantum Operations Per Second):
-
R = Q * fatP_l -
f: logical clock speed -
Q: the number of reliable logical qubits -
P_l: error rate of logical qubits
They have analyzed many use cases and broke them down in three categories:
- First Scientific Applications: Dynamic properties of Ising models: ~kilo rQOPS at \(10^{-8}\) error rate.
- More Scientific Applications: Groundstate properties of Fermi-Hubbard or Heisenberg model: ~Mega rQOPS at \(10^{-12}\) error rate.
- Practical Chemistry Applications: Quantum chemistry with 30-40 molecular orbitals: ~Giga rQOPS at \(10^{-18}\) error rate.
In the end, Wim commented that it’s important to have a link between algorithm and hardware developers: Big O notation is nice, but metrics such as rQOPS allow you to be physics-aware while being an algorithm designer. But also, they allow experimentalists to easily answer questions such as: “If I improve this aspect, what are the algorithmic consequences?”
Regardless of where you work in the stack, resource estimation is a compass that tells you what to work on.
Panel
For the panel, apart from Travis and Wim, we also had:
- Oliva Crawford from Riverlane
- Will Zeng from Quantonation
- Dave Clader from BQP Advisors
Here are some of my favorite insights.
Question: What are the biggest challenges in QRE?
- QRE is a process composed of many steps and at each step one needs to make a choice. Many of the components don’t exist yet. This makes making reasonable assumptions and approximations difficult.
- Communicating the results so they are reproducible and meaningful.
- Building tools is critical.
- Making the optimism concrete is important.
Question: What is the right approach to attack the scalability problem?
- Try to be as accurate as possible at the abstract circuit level. Ignore QEC, routing layouts, etc., just deal with the gates. This is a very useful place to start.
- We can have the best QRE but there is still a question of whether this is even the right program to run. Verification is an important open problem and gets harder as the system scales.
- Getting precise numbers takes time, and immediate feedback is super important. There’s a tradeoff between being precise and being fast about it.
- You need to have libraries to do fixed-point arithmetics and other basic subroutines to speed up the research
Question: How to communicate very big numbers (months of runtimes, billions of T-gates) in a way that’s productive and doesn’t scare people?
- We need to have metrics that we can work towards which will remain valid metrics all the way to the utility. Otherwise, from the outside, it looks like changing the goalpost.
- It’s also important that people get used to those numbers. We need to make it clear that we’re a long way from the FTQC calculations.
- The real value of doing concrete resource estimates is that once someone produces those resource estimates, the community jumps in and the numbers get improved. At some point we’ll hit some asymptotic barriers
Extra quotes worth mentioning:
- Often we find that when you look at all the details you find out that the algorithms actually don’t give you any speedup.
- Arguably this is the most important workshop of the week <3
Machinery
Sam Jacques
After a break we got into the “QRE Machinery” sessions. We started with a talk by Sam Jacques who’s Assistant Professor at the University of Waterloo.
The talk was about Sam’s experiences working on multiple projects, during his time at Microsoft, Oxford, and Waterloo. Sometimes it got pretty detailed, so rather than trying to reproduce the whole reasoning and story, I’ll just cover the main points:
- A huge cost driver in Shor’s algorithm is performing arithmetics
- You can either use low, assembly-level languages (like qiskit) or high-level (like Q#), but there’s nothing in between right now.
- Apart from calculating resources for a particular algorithm, we also need to check for its correctness.
- Fixing compilation bugs is extremely hard – Sam talked about a story of a particular bug in Q#, which took about 2 years to properly fix, as it was coming back in various flavors.
- Introducing feedback loops with classical measurements leads to new level of bugs in the algorithms and compilation.
- If one breaks a couple of abstraction layers and implements the algorithm at the level of surface codes, it allows for a whole new level of optimizations. However, it’s extremely tedious and manual, there are absolutely no tools to do this.
- People focus too much on T-count, and in some cases, T-depth and reaction speed are the real bottlenecks.
Summary slide from Sam:
- Automating resource estimations is hard
- No perfect trade-off between generality and accuracy
- It’s too early to pick architectures or assumptions
Sam’s QRE wishlist:
- Software to work with 2D surface codes
- More attention to routing and physical layout problems
- Free your minds from reversible classical computation
Daniel Litinski
Daniel Litinski is a Quantum Architect at PsiQuantum.
Daniel talked about his recent paper about elliptic curves, but this paper about active volume also provides a lot of relevant background. So if you’d like to get into real technical details, that’s where you should go. Here I’ll try to get across some major points from the talk.
Daniel started from talking about the differences between “active volume (AV) architecture” and “baseline architecture”. The two main points for me:
- In baseline architecture the speed of performing T gates is constant, but in AV architecture, thanks to non-local connections, speed can be increased by adding more qubits.
- In the baseline architecture our primary resources are T/Toffoli gates, in AV architecture our primary resource is, well, Active Volume. The ratio for AV to Toffoli counts differs from subroutine to subroutine. In general, it’s favorable for arithmetic, but it can be quite costly for lookup tables.
After this, he talked more about various compilation optimizations for the elliptic curve algorithm. Some of them are asymptotic in nature – they come from parallelization and would not apply if we wanted to break only one key at a time.
- Given that the first half of the computation will be the same for many keys, we can reuse it to break multiple keys (2x reduction).
- You only need to generate 208 out of 256 bits on a quantum computer, as the other 48 can be brute-forced on a classical computer. It costs less than a million CPU hours (also see Martin Ekera’s paper).
- Spread the cost of modular inversion (the most expensive operation in the algorithm) over multiple instances (~2.5 reduction).
- There’s a trick called “windowing” where we precompute some values classically and put them in a lookup table, which is cheaper to implement on a QC than calculating them on the fly.
Each instance of the algorithm uses about 3k logical qubits & 100m Toffoli gates / 7b blocks of AV. But the more keys we calculate in parallel, the smaller the number of Toffoli gates per key (see tricks above). Asymptotically it gets to about 50m Toffoli gates per key (at around 50k logical qubits). To put it in context, this is a relatively small number – RSA 2048 requires over a billion Toffoli gates and FeMoCo 10 billion Toffolis.
However, it’s worth noting, that some of these tricks only make sense in AV architecture – in baseline architecture such parallelization may increase overall computation cost.
At the end Daniel talked about physical resources from this table from his paper – no comments from me, just take a look at it:

I really encourage you to read Daniel’s papers – all his papers are very well written and pretty approachable (given the complexity of the topics), he’s definitely one of my top favorite paper authors (and was even before I started working with him!)
Thomas Alexander
Thomas Alexander is a Quantum Solutions Developer at IBM. For the last 5 years he worked on putting quantum systems online.
In contrast with previous talks, Thomas focused more on software-hardware interface. He was referring to some of the concepts from this paper.
Here’s a bunch of very good points he made during the talk:
- As the systems scale up, so does the complexity, and building a quantum computer requires connecting many subsystems.
- QRE is a tool that allows us to predict application requirements. In turn, application requirements allow us to predict system and subsystem requirements.
- There’s a co-design loop in designing a quantum computer – saying “I want to run this application” forces a series of design decisions down the stack. This is a hard optimization problem with tradeoffs everywhere.
- There is no “quantum computer” today. There is just a device. What turns it into a QC is plenty of calibration and characterization routines that bootstrap this device into a quantum computer.
- In the near term, you need to really optimize all the elements to make things work, so you need to understand many subsystems, which is hard.
- Today most QRE focus on circuits (logical or physical), but enabling higher-level abstractions will allow to reduce the information flow throughout the system. For example, when you’re sending info about expectation value instead of all the measurements, there’s much less info to be passed between subsystems.
- We need to start introducing reusable subroutines.
- Right now we use a small number of inputs for doing QRE, but from the perspective of operating the system, the number of parameters is much higher. However, on the existing devices each qubit is a special snowflake and to get any performance you need to finetune using knowledge about each qubit. We need to get to a world where all the qubits are fungible and we don’t need to worry about their individual characteristics.
- Quantum IRs – compilation should scale at most polynomially, but ideally linearly in terms of numbers of gates or qubits. Right now it’s pretty slow, we need to introduce better IRs to make this process more efficient.
- Most representations don’t support non-linear control flow, which will be a problem as we start thinking about more advanced protocols.
- To get the most out of the device it’s important to understand how your big program is being distributed among multiple smaller devices which control different aspects of the overall QC.
- To run those weeks-long algorithms, we will need to keep the devices up for days.
- Reliability and efficiency of machines are critical for long-running applications.
Tools
The last part of the workshops was a session where various people gave 5-10 minute presentations on the tools they’re developing and then some time for having discussions with the developers.
We had:
- Athena Caesura from Zapata AI presenting Bench-Q
- Matt Harrigan from Google presenting Qualtran
- Mariia Mykhailova from Microsoft presenting Azure Quantum Resource Estimator
- Kevin Obenland from MIT Lincoln Lab presenting pyLiqtr
- Michał Stęchły presenting PsiQuantum’s symbolic QRE tools.
While this section is short, I recommend checking out all of these tools and seeing if there’s anything useful there for you. If the topic of QRE is of interest to you, I really think it’s crucial to get acquainted with at least some of them!
Summary
There have been a couple of points that appeared in multiple places throughout the workshops, so I think it’s worth putting them all in one place:
- QRE is important, but it’s equally important to be confident that the programs we’re running are correct.
- We need better tools for performing QRE – and in the last part of the workshop we have seen that some of those tools are being created right now, hurray!
- We also need better abstractions and data formats.
- QRE is an important bridge between applications and hardware development.
- There are plenty of optimizations at the level of compilation that we still need to work out.
- There are many, many assumptions being made while running QREs, which undermines their reliability. But also given where we are, that’s the best we can get and it constantly gets better.
Closing notes
Overall, I am really happy with how the workshops went! It spurred a lot of interesting discussions, I hope we’ll organize another one in 2024. It’s great to see forming of the community around QRE! There was so much good energy around it, that I thought it would be good to help with the “community forming”. That’s why I’ve created a Discord server to facilitate discussions on the topic and perhaps spur some future projects. We even had our first talk. If you’d like to join it, this link will be active for 7 days after publication of the blog post. After that, please send me an e-mail to get an invite :)
And once again, huge kudos to the people who helped organize the workshop:
- Peter Johnson
- Simon Tsang
- Kevin Obenland
- Omar Shehab
- Mathias Soeken
Have a great day!
Michał